Vision AI Medical Research: Evaluating GPT-4 Vision for Dermatology Diagnostics
Partnered with Johns Hopkins Dermatology department to evaluate GPT-4 Vision accuracy in dermatological diagnostics, implementing specialized AI prompting techniques and building quantitative evaluation models.
The Client
Johns Hopkins University stands as one of the world’s premier medical research institutions. The Dermatology Department exemplifies this excellence, conducting cutting-edge research while providing specialized clinical care. The department’s faculty includes internationally recognized experts in skin cancer, autoimmune disorders, and dermatopathology.
With the rapid advancement of AI vision models like GPT-4 Vision, the research team recognized an opportunity to rigorously evaluate these technologies’ potential in medical diagnostics. They sought a technical research partner who could design and execute a comprehensive evaluation study for academic publication.
The Challenge
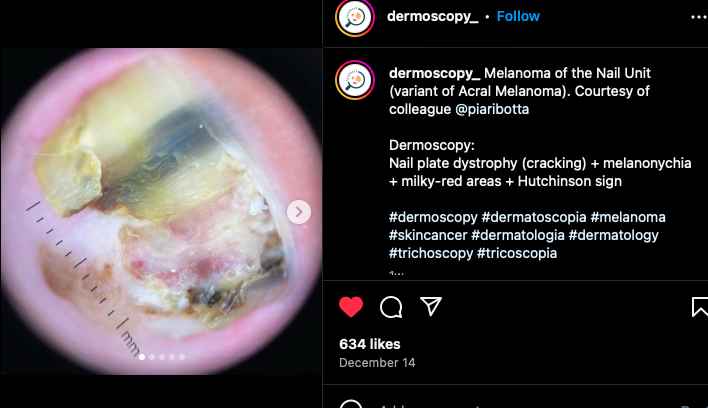
The research challenge centered on methodological rigor: designing an evaluation framework robust enough to generate publishable, scientifically valid conclusions. Medical AI evaluation is notoriously difficult—models that appear impressive in demos often struggle with real-world clinical diversity.
The technical infrastructure required assembling high-quality dermatological image datasets, optimizing GPT-4 Vision through advanced prompting techniques (few-shot and chain-of-thought), and creating a valid comparison framework against expert dermatologists. The evaluation had to account for the qualitative nature of medical diagnostics and provide segmentation analysis across disease categories.
Our Solution
We built robust technical infrastructure for image acquisition and processing, then optimized GPT-4 Vision through specialized prompting techniques tailored for medical diagnostics. Few-shot prompting provided example diagnoses to guide the model, while chain-of-thought prompting instructed explicit diagnostic reasoning: observe morphology, consider distribution, evaluate color/texture, generate differential diagnosis.
We coordinated parallel evaluation with Johns Hopkins expert dermatologists and built custom quantitative models to compare qualitative medical evaluations—extracting diagnostic decisions from both sources, normalizing them, and conducting segmentation analysis across disease categories.
The Impact
The research established that GPT-4 Vision achieved strong performance on conditions with distinctive visual presentations but struggled with conditions requiring subtle clinical judgment, particularly early-stage melanoma. Expert physicians consistently outperformed AI on complex presentations—validating that these tools show promise as screening aids but aren’t ready to replace specialized expertise.
The study contributed to academic medical AI literature at a critical moment, providing rigorous peer-reviewed evidence as healthcare institutions evaluated AI adoption. The research reinforced Johns Hopkins’ reputation as an innovator in medical technology evaluation.